xpath学习笔记
学习参考
转自Python爬虫利器三之Xpath语法与lxml库的用法
xpath语法参考w3school
选取节点
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。
下面列出了最有用的路径表达式
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点 |
| / | 从根结点选取 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性 |
实例
在下面的表格中,我们已经列出了一些路径表达式以及表达式的结果:

实例Demo
1 | <bookstore> |
实例测试
在下面的表格中,我们已列出了一些路径表达式以及表达式的结果:

谓语
谓语用来查找某个特定的节点或者包含某个指定的值的节点。
谓语被嵌在方括号中。
实例
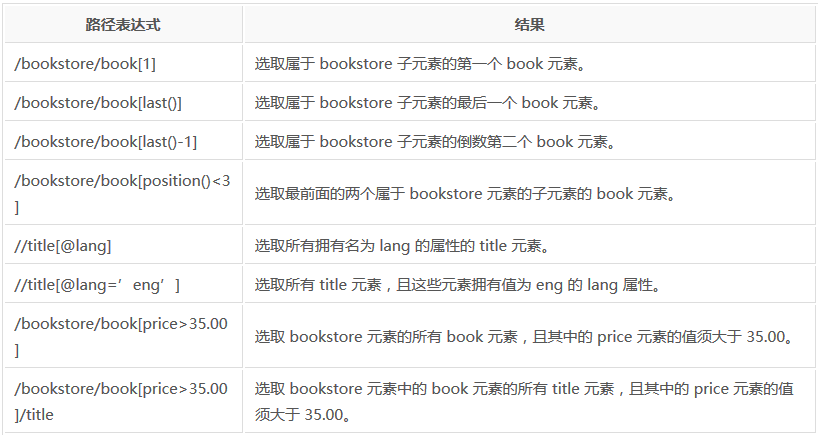
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
选取未知节点
XPath 通配符可用来选取未知的 XML 元素。
| 通配符 | 描述 |
|---|---|
| * | 匹配任何节点元素 |
| @* | 匹配任何属性节点 |
| node() | 匹配任何类型的节点 |
| 通配符 | 描述 |
|---|---|
| * | 匹配任何节点元素 |
| @* | 匹配任何属性节点 |
| node() | 匹配任何类型的节点 |
实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/* | 选取bookstore元素的所有的子元素 |
| //* | 选取文档中的所有元素 |
| //title[@*] | 选取所有带有属性的title元素 |
选取若干路径
通过在路径表达式中使用“|”运算符,可以选择若干个路径
实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 | |
|---|---|---|
| //book/title \ | //book/price | 选取 book 元素的所有 title 和 price 元素。 |
| //title \ | //price | 选取文档中的所有 title 和 price 元素。 |
| /bookstore/book/title \ | //price | 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。 |
Xpath实例测试
测试Demo:1
2
3
4
5
6
7
8
9<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
<1> 获取所有的<l\>标签1
response.xpath('//li')
<2> 获取 <li> 标签的所有 class1
2
3
4
5response.xpath('//li/@class')
运行结果
['item-0', 'item-1', 'item-inactive', 'item-1', 'item-0']
<3> 获取 <li> 标签下 href 为 link1.html 的 标签1
2
3
4response.xpath('//li/a[@href="link1.html"]')
运行结果
<4> 获取 <li> 标签下的所有 <span> 标签
注意这种写法是不对的
response.xpath('//li/span')
因为/是用来获取子元素的,而并不是
<li>的子元素,所以要用双斜杠,如下所示:
response.xpath('//li//span')
运行结果:
[<Element span at 0x10d698e18>]
<5> 获取<li>标签下的所有class,不包括<li>
result = response.xpath(''//li/a/@class')
print result
运行结果:
['blod']
<6> 获取最后一个<li>的<a>的href1
response.xpath('//li[last()]/a/@href')
运行结果:
['link5.html']
<7> 获取倒数第二个元素的内容1
2result = response.xpath('//li[last()-1]/a')
print result[0].text
运行结果:
fourth item
<8> 获取class为bold的标签名1
2result = response.xpath('//*[@class="bold"]')
print result[0].tag
运行结果:
span
通过以上实例的练习,能够对XPath的基本用法有了基本的了解,也可以通过text()方法获取元素内容。